Recreation of call records from radius log files
Emin Gabrielyan
Created and modified on 2011-02-21 by Emin, on 2011-02-22 by Emin, on 2011-02-23 by Emin
Recreation of call records from radius log files.
How to update MS Word DOC documents published on the web
How to add non public data into public pages
Update of 2011-02-23
The new version threats differently the rare cases of answered calls for which the connected vendor leg appears twice. Such a scenario may occur normally in case of call forwarding. Otherwise, a double vendor charge may occur also for delayed accounting records. In this update we sum up the costs together instead of considering only a cost of the last instance. We do not however sum the durations [sec].
[zip] (9.47MB Protected)
The script of the new version also verifies for new updates before its execution and not after. If new updates are available, it updates itself, and exits. The next execution will come shortly thanks to crontab, and the script will start doing its job.
$ diff -y --suppress-common-lines -W 165 ba07.sh.txt ba08.sh.txt
# on 2011-02-22 by Emin | # on 2011-02-22 by Emin, on 2011-02-23 by Emin
ver="110222/ba07" # | ver="110223/ba08" #
> #
> #
> running=`ps -o pid,comm,cmd -C calls.sh | tail -n +2 | wc -l` #
> if [ $running -eq 1 ] #
> then #
> exit #
> fi #
> #
> cd $work #
> diff -q Downloads/calls.sh . > /dev/null || exec cp Downloads/calls.sh . #
> #
> #
> #
> #
> #
$cost{$h323}=$cost; | $cost{$h323}+=$cost;
cd $work # | # cd $work #
exec cp Downloads/calls.sh . # | # exec cp Downloads/calls.sh . #
$
The self-update at the end is removed. The new version is more reliable, as there is no risk of updating the script while its other instance is running.
Files
The current version of the script:
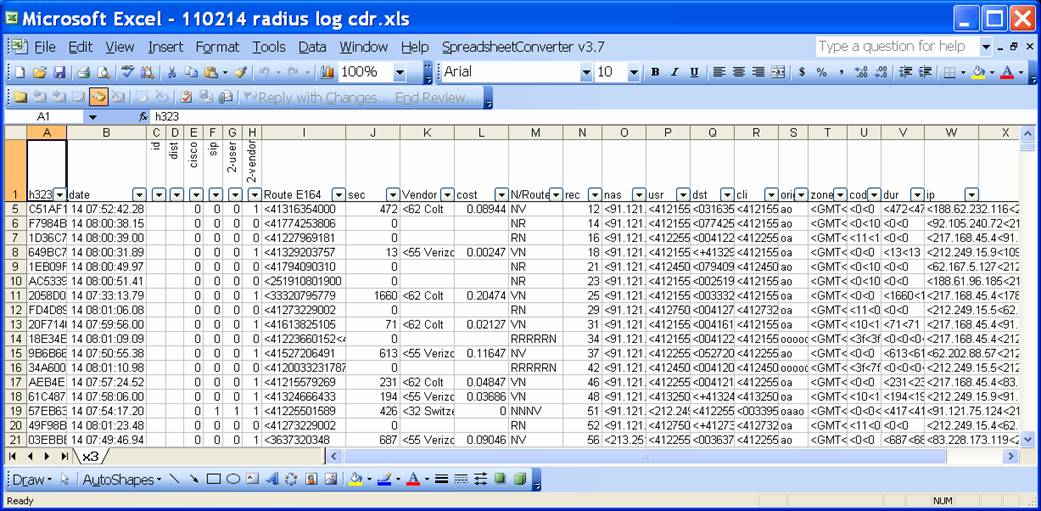
The log accompanying the new version:
Introduction
A phone call passing through the network of switzernet.com can often traverse several telephony nodes before being connected with the called party. Each node on the path communicates with an AAA radius server via a radius protocol. The radius server logs all accounting packets received from its nodes. The daily logs of the radius server represent files of several gigabytes in size. These log files contain the records of the radius packets belonging to different calls and received from different network nodes. The records on packets are stored in the order of their arrival. An individual call history can be reconstructed thanks to the H.323 identifications of calls, which are unique per call. The H.323 identification number is preserved throughout the entire path of the call within the network of switzernet.com and with a proper interconnection, even beyond its network. An already published work introduces a system for synchronizing and archiving the radius log files, which are otherwise not conserved on the main AAA server(s) [1], [2], [3]. Given that we already have the radius log files on a separate server, this document is dedicated on the introduction of the script that can reconstruct on the fly the call details from the synced and progressively updating radius log files. The script is running on the fraud-control.switzernet.com and is in the same code depository together with the radius log sync script [4], [5], [6] (starting from the version of 2011-02-19.
The table below describes the call reconstruction script. The newer versions are released and you have to consult the code depository for the latest version.
|
Script |
Description |
|
#!/bin/bash # Keep this DOS line (two UNIX lines) unchanged # Copyright (c) 2011 by Emin Gabrielyan of switzernet.com # Created and modified on 2011-02-19 by Emin, on 2011-02-21 by Emin # Version: ba02 # # |
The hash signs are added at the end of each line for avoiding in UNIX bash interpreter errors due to MS-DOS style newlines. |
|
sync="/home/var/log/radius" # work="/home/var/log/radius/work" # # cd $sync # |
The folder $sync is the place where radius log files are being copied from the main AAA server [1], [2], [3]. |
|
# runlog="`ls *,*,*,*,running,radius.log 2>/dev/null`" # # if [ -z "$runlog" ] # then # exit # fi # |
We check first if there is a running log file, i.e. a log file, which is currently open on the remote AAA server. If no running radius file found, we have nothing to do, so we exit. Normally there is always a running radius log. |
|
# pref=`echo $runlog | cut -d, -f1-4` # |
The prefix of the running log file is isolated. The next is an example of a running log filename [110221,090053,201742,0,running,radius.log]. The first four, comma separated fields represent the date in yymmdd format, the time in hhmmss format, the remote file descriptor on the principal radius server, and the remote file offset in bytes (normally must be zero, meaning that the file is synced from the beginning). |
|
# cdr="$pref,running,calls.csv" # # if [ -f "$cdr" ] # then # exit # fi # |
If a call file, corresponding to the currently running radius log file already exists, we have nothing to do, so we exit. |
|
# opt="-n 222000" # opt="-c +0 --follow=name --sleep-interval=2 --max-unchanged-stats=10" # |
Here are options of the tail command. The first assignment is used for testing. The second assignment is for the production version. The option “-c +0” tells to run the tail from the beginning of the file. The option “--follow=name” tells first that the file must be kept open and continuously scanned for new lines. The same option tells also that if the file is not updated for a while, then it must be reopened again to check whether its name is changed or not. If the file with the initial name is not found, the tail program stops. By default, without such options, if the filename is changed the tail continues to process the file thanks to the unchanged file descriptor. This option forces a termination of the tail program upon a renaming of the source file. The sleep interval option dictates the number of seconds to wait before new reading attempts every time the EOF is reached. The last option contains the number of idle iterations to skip (when no updates are detected) before trying to reopen the file with its name. |
|
tail $opt $runlog | perl -e ' %mm=("Jan",1,"Feb",2,"Mar",3,"Apr",4,"May",5,"Jun",6, "Jul",7,"Aug",8,"Sep",9,"Oct",10,"Nov",11,"Dec",12); |
Here we are parsing the input records to the Perl script as long as they arrive from the radius server. The Perl script is responsible for the main job of the call reconstruction. The hash array initialized at the beginning of the script is used for converting the dates read from the log file in mmm dd yyyy format into dates in yyyy-mm-dd format. |
|
sub z{ ($a,$node,$call,$stop)=("",0,0,0); } &z; |
The Perl script reads the input log file line by line. You will see that we define REGEX patterns telling whether the currently read line can be eventually useful. If the line is judged as possibly useful, it must be added into a multi-line scalar variable $a. When sufficient elements are collected into $a, the string is processed for retrieving the useful elements and sorting them out in the cache of detected calls. After processing the buffer string $a must be reset to empty for collection of new sets of useful lines. While collecting the lines into the string $a, the variable $node is set into 1, if the data collected corresponds to a record coming from a radius node (otherwise the records are of no interest). The variable $call is set to 1, if the collected data is proven to correspond to a call (otherwise, if for example it is about a SIP registration, the data is out of interest, and we ignore all buffered lines). Finally the variable $stop is set to 1, if it is about a radius STOP records arriving at the end of the call (we skip the START records as the STOPs are sufficient). The procedure &z is used to reset all variables after their processing. It is called from the subroutine &flush. |
|
$rec=0; $recout=500; |
The variable $rec stores the number of the current radius record that is considered for collection. The next variable is the size of the cache. The records older than $recout are dumped into the CSV file and are emptied from the cache of calls. We consider that no two STOP records belonging to the same call can be separated by more than 500 records. Obviously, the STOP can be quite far from its START counterparts, but as we are limited by only STOP records, the limit of 500 must be sufficient. |
|
# $fields="%35s,%23s,%13s,%4s,%13s,%8s,%7s,%5s,%s,%s,%s,%s,%s,%s,%s,%s,%s\n"; $fields="%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s\n"; |
This variable specifies the output filed format. The first version is useful for displaying the text file on the screen. However, for CSV output files, the second version must be used (as spaces in front of headers and especially date variables cause problems in Excel). |
|
sub headers{ printf $fields, "h323", "date", "Route E164", "sec", |
Here we print all headers to be saved in the output CSV file. The first field is the unique ID of the call preserved throughout its path throughout all nodes of the network. The 2nd field contains the date and time (of the last STOP record associated with the call in GMT time zone). The 3rd filed contains the destination number in E.164 format. This element can be collected only from an AAA packet corresponding to the outgoing leg to a vendor. In case of multiple attempts, such packets can be repeated several times. For each such packet, the E.164 field will contain a repeated copy of the destination number concatenated to the previous value of the field. Thus the filed can look a follows “<14197121783<14197121783” indicating on two routing attempts. The concatenated numbers are usually the same E.164 numbers indicating on several routing attempts. However, the numbers concatenated into this field for the same call record can be sometimes different. Such situations occur in case of automatic call forwarding and two or more different destination numbers may appear in the chain. The fourth field is the duration of the call collected from the last record containing the E.164 routing message. |
|
"Vendor", "cost", |
If the call is connected, a vendor charge record appears in the log file associated with the AAA packet of the outgoing leg toward the vendor in question. The 5th and 6th fields are retrieved from such records. The field “Vendor” contains the vendor ID number followed by its name in the database. The “cost” field contains the amount charged to the “Vendor” account. |
|
"N/Route/Vendor", "rec", |
The 7th filed contains a sting consisting of three possible characters. There are as many characters as there are packets associated to the current call. The character “V” corresponds to the packet associated to the vendor leg for the charged calls. The character “R” corresponds to the routing attempt, which did not result into a connected/charged call. The character “R” can repeat very often (once per routing/rerouting attempt). The character “V” repeats rarely. It can repeat normally only in case of forwarded calls and otherwise must either not appear or appear only once. For all other call legs, the character “N” is used (interpret it as node, none, or network). |
|
"nas", "usr", "dst", "cli", "orig", "zone", "code", "dur", "ip", } &headers; |
The fields from 9 to 17 store the values associated to the current call retrieved from different AAA packets by joining the new values to already collected sequence of values within the field in question. The values are added (concatenated from the right) into their corresponding fields in order of their arrival. The separator “<” is used (except for single character “orig” field without separators). The field “nas” contains the IP address(es) of issuing network nodes. The filed “usr” contains the account(s) to be charged for the call. The field “dst” contains the phone number(s) as dialed (depending on the scenario, the same number can appear once with a “00” prefix, for the record corresponding to the user leg, and another time with “+” prefix for a record corresponding to a vendor leg). The field “cli” corresponds to the calling number(s) (may appear in different formats). The field “orig” is a sequence of two possible characters, “a” for incoming legs, and “o” for the outgoing legs (both, with respect to the node). Assuming the node is not a transit; “a” would mean a customer and “o” a vendor. The field “zone” concatenates the time zones of nodes in order of their arrival (from left to right). The filed “code” concatenates the H.323 termination codes. The field “dur” contains the durations, which are usually the same, except for the IVR systems implemented on nodes. The field “ip” was the most motivating field for launching this project that aims at a design of an automatic anti-fraud system. It contains the remote IP address of the leg. Note that its value can be the IP address of the customer for an originating leg, of the vendor for the terminating leg, or of the node for the transiting leg. It can be also set to “sip-ua” for a termination to switzernet.com’s network. |
|
sub save{ for my $i (keys %rec) { if($rec{$i}<$rec-$recout) { printf $fields, $i,$date{$i},$e164{$i},$sec{$i},$vendor{$i},$cost{$i},$leg{$i},$rec{$i}, $nas{$i},$usr{$i},$dst{$i},$cli{$i},$orig{$i},$zone{$i},$code{$i},$dur{$i},$ip{$i}; delete $date{$i}; delete $e164{$i}; delete $sec{$i}; delete $vendor{$i}; delete $cost{$i}; delete $leg{$i}; delete $rec{$i}; delete $nas{$i}; delete $usr{$i}; delete $dst{$i}; delete $cli{$i}; delete $orig{$i}; delete $zone{$i}; delete $code{$i}; delete $dur{$i}; delete $ip{$i}; } } } |
This procedure is called upon the reception and accomplishment of the processing of each interesting AAA record. This function scans all call records of the hash array (indexed by H.323 call identification numbers) not updated since $recount (500) new records. Such old records are saved in the CSV file (printed into the standard output), and deleted from the hash array representing the cache of calls. New AAA packets linked to the same call, if they arrive, cannot be associated with the same record anymore and a new fresh record will be created. Such situations can be found in the output CSV file by examining the eventual repetitions of the unique H.323 call ID. |
|
sub insert{ $nas{$h323}.="<".$nas; $usr{$h323}.="<".$usr; $dst{$h323}.="<".$dst; $cli{$h323}.="<".$cli; $orig{$h323}.=$orig; |
This procedure is responsible for associating the values of a received AAA packet to the call record stored in the hash array. For each AAA packet judged as useful, we retrieve all key parameters in scalars $nas, $usr, etc. This retrieval (decomposition of the AAA packet into parameters) occurs in the procedure &define, which will be introduced later. Here we add the already retrieved parameters into the hash array of calls. As already described before, the $nas{$h323} field contains the concatenations of the NAS-IP-Address values of all AAA packets (associated with the call in question) joined together in the order of their appearance in the log file (in the order of the reception by the radius server). The $usr{$h323} field contains the concatenations of all User-Name attributes in the same order (of arrival). The same is valid for Called-Station-Id, Calling-Station-Id, and h323-call-origin radius attributes. The number of concatenations and the order of the elements is the same for all the five fields shown on the left. |
|
$date{$h323}=sprintf("%d-%02d-%02d %s",$yyyy,$mm{$mmm},$dd,$time) if($zone eq "GMT" || !$date{$h323}); |
The $date{$h323} contains one single date and time value. We try to record the date only in GMT time zone. |
|
$zone{$h323}.="<".$zone; $code{$h323}.="<".$code; $dur{$h323}.="<".$dur; $ip{$h323}.="<".$ip; |
Similarly to $nas{$h323}, and many other attributes, we collect into each field also the values of the time zone, call termination code, session time, and remote IP address, all in the order of arrival, and separated by “<” signs. Note that the value of the remote IP address can correspond to the user’s address emitting the call, to another node (in case of a transit), to a vendor connection (for an outgoing leg), or to a keyword “sip-ua” in case of termination toward a registered customer. The keyword “sip-ua” corresponds to the vendor switzernet.com. |
|
if(defined $sec) { $e164{$h323}.="<".$e164; $sec{$h323}=$sec; } |
The $e164 and $sec values will be defined at least once per call for each routing attempt. The value will be present only for an AAA packet corresponding to the vendor leg. |
|
if(defined $cost) { $vendor{$h323}.="<".$vindex." ".$vname; $cost{$h323}=$cost; } |
Whenever the call is connected, the vendor info will emerge together with the cost being charged to us by the vendor. |
|
$leg{$h323}.=$e164?($vindex?"V":"R"):"N"; |
This string describes for each call the sequence of recorded AAA packets. The number of characters in this string corresponds to the number of values stored in $nas{$h323} field and several other similar fields being updated by every accounting STOP packet associated to the call. The number of “V” characters will correspond to the number of elements in the $vendor{$h323} field. The number of elements stored in the $e164{$h323} field is the sum of the numbers of the “R” and “V” characters. |
|
$rec{$h323}=++$rec; |
The $rec{$h323} field contains the sequential number of the last AAA packet that updated the call entry. This number is used by the &save procedure (described above) for determining whether to empty the cache from the call entry or continue keeping the entry it in the cache hoping that other radius packets associated with the call may still arrive. |
|
&save; |
After processing each valid STOP packet we call the procedure &save, which empties the cache from all records by dumping them into the output CSV file. |
|
} |
This is the end of the &insert procedure. |
|
sub debug{ print "\n[".(($e164)?"V":"C")."]\n"; print "nas=$nas\n"; print "usr=$usr\n"; print "dst=$dst\n"; print "cli=$cli\n"; print "orig=$orig\n"; print "date=$yyyy-$mmm-$dd $time\n"; print "code=$code\n"; print "h323=$h323\n"; print "dur=$dur\n"; print "ip=$ip\n"; print "e164=$e164\n"; print "sec=$sec\n"; print "vindex=$vindex\n"; print "vname=$vname\n"; print "cost=$cost\n"; print $a; } |
This function is obsolete and must not be used in conjunction with the CSV output file. Here we print all values retrieved from the radius packet as well as the multiple-line buffer $a of the collected log lines. |
|
sub define{ ($nas,$usr,$dst,$cli,$time,$zone,$mmm,$dd,$yyyy,$dur,$ip,$e164,$sec,$vindex,$vname,$cost)=(""); |
From each useful radius packet, we can hunt up to 16 key parameters. Before starting the hunting, we delete all corresponding scalars. They all become undefined, except the $nas, which anyway cannot miss in a valid AAA packet. |
|
$nas=$1 if($a=~/^NAS-IP-Address *= *'\''(.*)'\''/m); $usr=$1 if($a=~/^User-Name *= *'\''(.*)'\''/m); $dst=$1 if($a=~/^Called-Station-Id *= *'\''(.*)'\''/m); $cli=$1 if($a=~/^Calling-Station-Id *= *'\''(.*)'\''/m); $orig=$1 if($a=~/^h323-call-origin *= *'\''(.).*'\''/m); |
All useful lines of the log file for a radius packet are already collected in a multiple-line brut buffer $a (you will see it below). This procedure is responsible for picking the parameters from $a whenever they are defined. The variables $nas, $usr, $dst, $cli, and $orig, will be defined and initialized by their corresponding attributes found (if any) in the multiple-line buffer $a. |
|
($time,$zone,$mmm,$dd,$yyyy)=($1,$2,$3,$4,$5) if($a=~/^h323-connect-time *= *'\''[.]?([0-9:.]*) +([^ ]+) +[^ ]+ +([^ ]+) +([0-9]+) +([0-9]+)'\''/m); |
The five variables representing the date and time will be set all together, only if the h323-connect-time attribute is found and has the expected format. |
|
$code=$1 if($a=~/^h323-disconnect-cause *= *'\''(.*)'\''/m); $h323=$1 if($a=~/^h323-conf-id *= *'\''(.*)'\''/m); $dur=$1 if($a=~/^Acct-Session-Time *= *'\''(.*)'\''/m); $ip=$1 if($a=~/^h323-remote-address *= *'\''(.*)'\''/m); |
If the concerned attributes exist, the $code, $h323, $dur, and $ip variables will be defined correspondingly. |
|
($e164,$sec)=($1,$2) if($a=~/: Call to '\''([^'\'']*)'\'' with duration ([0-9]+) seconds /); |
The two variables $e164 and $sec are coupled and are either both defined or both undefined. They emerge only for the AAA packets corresponding to an outgoing vendor leg (successful or not). |
|
($vindex,$vname,$cost)=($1,$2,$3) if($a=~/: Charging vendor ([0-9]*) '\''(.*)'\'' ([0-9.]*)/); |
The three variables $vindex, $vname, and $cost are either defined together or all remain undefined. These variables emerge for AAA stop packets corresponding to a successfully connected outgoing vendor leg. |
|
} |
This is the end of the procedure &define that was responsible for hunting out all useful parameters from the current AAA packet record. |
|
sub flush{ if($node&&$call&&$stop){ &define; &debug if(0); &insert; } &z; } |
This procedure is called whenever the log file signals an end of an AAA record and associated billing messages. In case the lines collected in the variable $a correspond to a record from a radius node (NAS-IP-Address is present), correspond to a call (h323-conf-id is present), and are accounting records of the type STOP, we process the buffer sting. As described above, the procedure &define hunts out all useful parameters and the procedure &insert associates the hunted parameters with the corresponding call stored in the hash array. The procedure &insert will also empty the cache progressively by writing its content into the output CSV file by calling the &save function after each processing. At the end, the buffer of collected input lines and its flags are all set to zero by the procedure &z and the buffering will restart from the scratch. |
|
while(<>){ &flush if(/^$/); $node=1 if(/^NAS-IP-Address/); if($node) { $a.=$_ if(/^(NAS-IP-Address|User-Name|Called-Station-Id|Calling-Station-Id|h323-call-origin|h323-connect-time|h323-disconnect-cause|h323-conf-id|Acct-Session-Time|h323-remote-address)|:( Call to | Charging vendor )/); $call=1 if(/^h323-conf-id *= *'\''.{35}'\''/); $stop=1 if(/^Acct-Status-Type.*Stop/); } } &flush; |
Here is the main script. We read the input as long as there is something to read. Recall that the input of our Perl script is the output of the tail program providing us progressively the radius messages. A careful stat on the radius log file showed that the sets of log lines corresponding to processing of single packet never contain an empty line and that such sets are separated by empty lines. Therefore whenever we reach an empty line we process the lines collected so far in the buffer with the &flush subroutine. The subroutine is called also when the end of the input file is reached. The three flags $node, $call, and $stop are set progressively to 1 if the record being read proves to correspond to a packet received from a node, if it is about a call with a valid H.323 call identification number, and if it is an accounting message of the type STOP. The &flush subroutine will trigger the processing of collected lines only if all three flags are set to 1, the buffer is deleted and the flags are reset to 0. The input lines are collected into the buffer variable $a, only if they contain one of the interesting key attributes or routing decisions. |
|
$rec+=$recout+1; &save; print "EOF\n"; |
At the end of processing of the input file we definitively empty the cache of calls by artificially setting the current record number sufficiently far in the future such that the &save subroutine will consider all call entries of the hash array sufficiently old for being dumped into the CSV file. |
|
' > $cdr # |
Here is the end of the Perl script. The output of the script is redirected into the CSV file of call records. |
|
# # cdrclose="$pref,`date +%d%H%M%S`,calls.csv" # cdrclose="$pref,rotated,calls.csv" # # mv "$cdr" "$cdrclose" # |
Here we rename the file by replacing the keyword “running” by “rotated”. We will reach this point shortly after the radius log file itself is renamed into “rotated”. This occurs once a day. The first assignment of the $cdrclose variable is obsolete and was useful only for testing. |
|
# # logs=`ls *,*,*,*,rotated,radius.log 2>/dev/null | wc -l` # unzipped=45 # |
As the CDR file is created, we are now counting the number of rotated radius log files. We also specify at most 45 unzipped radius log files. |
|
if [ $logs -gt $unzipped ] # then # tozip=$((logs-unzipped)) # |
If the number of log files is more than the specified limit of unzipped log files, we compute the number of log files to zip. |
|
ls *,*,*,*,rotated,radius.log | head -$tozip | while read f # do # gzip $f # done # fi # |
As the files are ordered alphabetically, and the files are prefixed by the date in yymmdd format, we need only to take the first $tozip files from the list of radius log files and compress them one by one. |
|
# # # cd $work # |
The script returns to the working directory. |
|
exec cp Downloads/calls.sh . # # |
This is a very important command line and the use of “exec” is obligatory here. By this command, the script does a self-update. Without the use of “exec” the script risks to update its content and continue the execution of the script file on from the current offset. If the new file is longer than the current one, the behavior of the script will be unpredictable and very dangerous. The “exec” command erases the memory content of the current process completely and all open file descriptors will be closed (including the one responsible for reading the current script by the bash program). The entire process will be replaced by the “cp” command. |
The crontab entries of the fraud control server are shown below.
|
Script |
Description |
|
fraud-control:/home/var/log/radius/work# crontab -l # m h dom mon dow command # |
Listing the crontab entries |
|
*/3 * * * * cd /home/var/log/radius/work; ./run.sh >> std.log 2>> err.log |
The radius log’s synchronization script is called every 3 minutes. This script is also responsible for downloading the new updates. |
|
*/5 * * * * /home/var/log/radius/work/calls.sh |
The script of the generation of call records is called every 5 minutes. The script will exit if it detects that another copy is already running. |
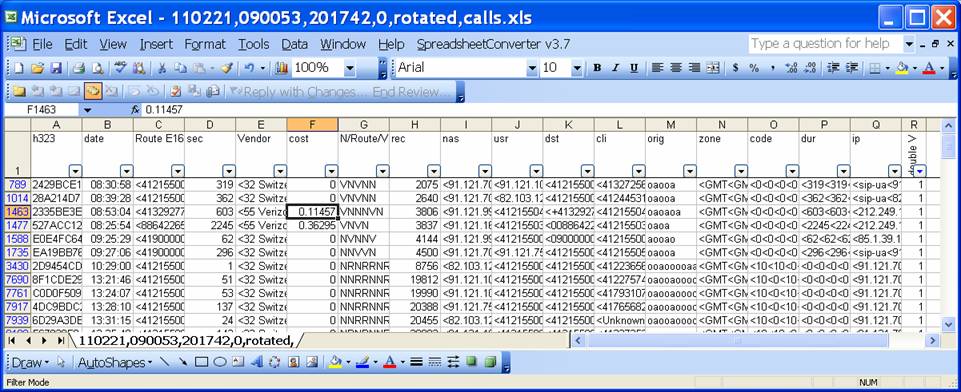
An example of the output file is shown below. The five fields of columns ‘C’ to ‘H’ were added afterwards in the Excel file for additional examinations. For each shown line, we see the destination number in E.164 format, the duration in seconds (field “sec”). The vendor ID and name as well as the cost for all answered calls appear in the snapshot below under the columns ‘K’ and ‘L’. These two fields appear only for answered calls. The next column shows us a sequence of characters representing the radius message types associated with the call. There are as many characters in the string as there are radius records received for the call. The character “R” in the sequence indicates on a failed routing attempt and the character “V” on a successful attempt (both being associated with an outgoing leg toward a vendor). The field “rec” appearing under the column ‘N’ of the snapshot below is the sequential number of the last AAA message associated with the call. Each of the fields under columns from ‘O’ to ‘W’ contains a sequence of values of a specific radius-attribute progressively picked up stuck together from the new AAA messages as they arrive.
[zip] (Protected)
Files
The versions of the script available while publishing this document (consult the code depository for the latest version):
The development process log, verifications, and the early versions of the script in AWK and in Perl:
References
Recreation of calls from radius log files (this page):
http://switzernet.com/3/public/110222-radius-log-cdr/
http://unappel.ch/2/public/110222-radius-log-cdr/
http://parinternet.ch/2/public/110222-radius-log-cdr/
Synchronization and backup of the rotating radius log file:
http://switzernet.com/3/public/101228-radius-log/
http://unappel.ch/2/public/101228-radius-log/
http://parinternet.ch/2/public/101228-radius-log/
How to update MS Word DOC documents published on the web
Find in the FTP folder the latest version of the DOC file index$N.doc having the largest value of $N. Create the next version by copying it to index$((N+1)).doc. Start modifying the new copy. Add in the header of the DOC the date of the modification and your first name. Point the last modification date to an HTML file index$((N+1).htm (to be created) using Ctrl-K shortcut. If your first name appears the first time, add your full name (first name + last name) in the header, below the list of full names appearing after the title. Save the DOC file in HTM format. Select the Web Page Filtered type when saving. Copy the index$((N+1).htm file into index.htm. Delete the old index.htm if it exists. If your web page was accompanied by images, a folder index$((N+1)_files will be copied automatically while you copy the HTM file. Delete the copy of the folder. Keep only the index.htm file as copy.
If you have additional files accompanying your document, find the latest version of the data$M folder. Create an empty folder with a successive number data$((M+1)). Put all your files you wish to refer to in the new folder. Add links to your files located in data$((M+1)) folder.
Apart the index$N files and data$M folders, the main folder of the document must contain a BAT file named Published.bat. It contains the FTP links. An example is shown below:
explorer ftp://switzernet.com/3/public/110222-radius-log-cdr/
explorer ftp://unappel.ch/htdocs/2/public/110222-radius-log-cdr/
explorer ftp://parinternet.ch/parinternet.ch/2/public/110222-radius-log-cdr/
There must be also a shortcut file, one per HTML clone:
You are encouraged to publish your documents on three servers but at least on two different servers.
How to add non public data into public pages
Often protected data needs to accompany a public document. Do zip the non public files into an yymmdd-$name.zip file, where $name is a clear, unique, and short description of the content. Upload the file into an yymmdd-files folder under [company] or [support] protected areas. If the yymmdd-files folder does not exist, is too old, or is too big, you are free to create a new one. The files in such folders are individual files unrelated to each other.
Such ZIP files, referred from public pages, must also contain URL shortcuts to the pages where from they are referred. This will permit to understand where from the file is used. Add a shortcut for each URL clone. If there are different public pages referring to the same ZIP file, organize the shortcuts into subfolders within the zipped file. Add also a shortcut to the ZIP file itself.
Glossary of symbols
AAA stands for authentication, authorization and accounting
AWK stands for the names of its authors: Aho, Weinberger, and Kernighan
CDR stands for the call detail recording
CSV stands for comma separated values
EOF stands for end of file
IP stands for Internet protocol
IVR stands for interactive voice response
PERL stands for practical extraction and report language
REGEX stands for regular expressions
URL stands for uniform resource locator
* * *
![]()
Copyright © 2010 – 2011, Switzernet.com