Sélection des champs utiles des e-mails de parrainage
Created on 2009-08-18 by Nicolas Jorand
Switzernet
Pour connaître le nombre de parrainage qu’un client a fait, nous commençons par rechercher les clients qui sont parrainés. Pour ceci, nous filtrons les e-mails et sélectionnons ceux qui ont "Subscribe" comme expéditeur et qui ont un parrain (pour connaître les filtres aller sur http://switzernet.com/company/090817-comparatif-filtre-mail/). Une fois ces e-mails récupérer, plusieurs informations dans le header nous intéressent : l’e-mail du destinataire, le sujet et la date. Ce qui suit explique comment récupérer ces informations et les mettre dans un fichier pour Excel.
 Pour l’instant
cette documentation ce base sur des tests effectués sur environ 100 e-mails et
non sur tous, soit plus de 1800.
Pour l’instant
cette documentation ce base sur des tests effectués sur environ 100 e-mails et
non sur tous, soit plus de 1800.
Méthode via Mozilla Thunderbird (plus compliquée)
2) Extraction des informations utiles
Méthode via Outlook (plus simple)
[recherche_mail]Rechercher les e-mails
Il faut commencer par récupérer les e-mails à l’aide des filtres. Dans Thunderbird, commencez par créer un nouveau dossier dans votre compte e-mail (pour tout ce qui suit, utilisez votre compte IMAP). Il servira à stocker une copie des e-mails qui doivent être traités. Ensuite, allez sur le compte de contracts puis lancez une recherche (clique droit->Search) :
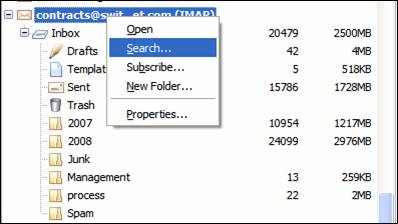
Vérifiez que la recherche se fait bien dans contracts@switzernet.com et que Match all of the following est cocher :
![]()
![]()

Maintenant appliquez les filtres de http://switzernet.com/company/090817-comparatif-filtre-mail/. Pour chaque résultat, sauvegardez-le comme dossier de recherche dans votre compte e-mail. Cliquez sur Save as Search Folder :
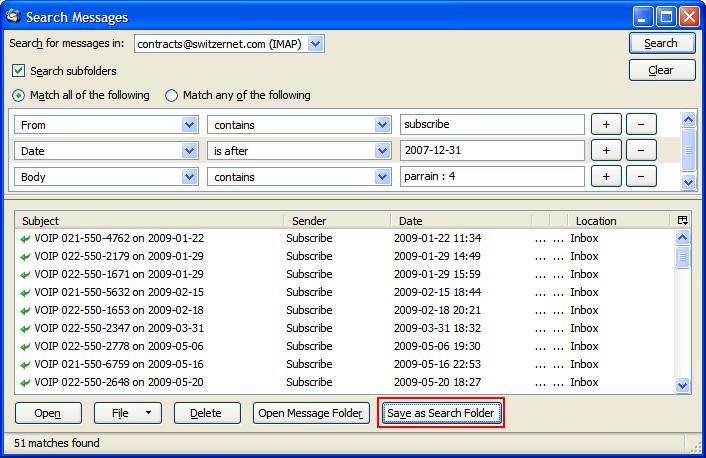
Entrez un nom pour votre recherche et sélectionnez l’Inbox de votre compte e-mail, puis appuyez sur Ok :
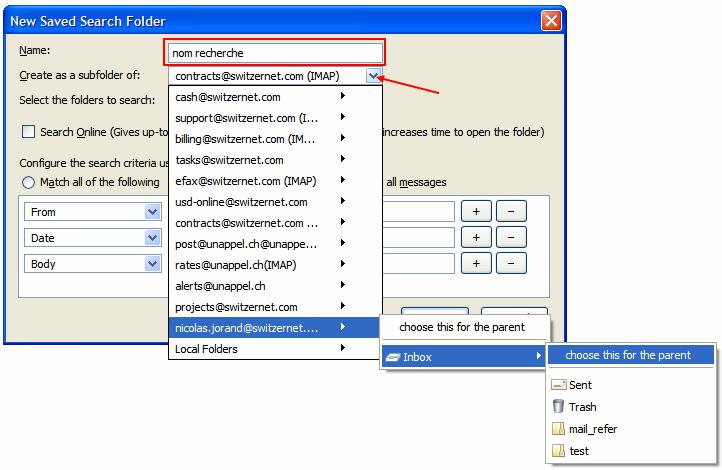
Une fois que vous avez sauvegardé toutes les recherches que vous vouliez faire, allez dans votre compte e-mail et copiez les e-mails contenus dans votre Search Folder et mettez-les dans le dossier que vous avez créé au début. Commencez par sélectionner tous les e-mails du Search Folder clique sur un e-mail puis ctrl+a. Ensuite faites clique droit sur la sélection->Copy to et choisissez votre dossier. Répétez l’opération pour tous vos Search Folders :
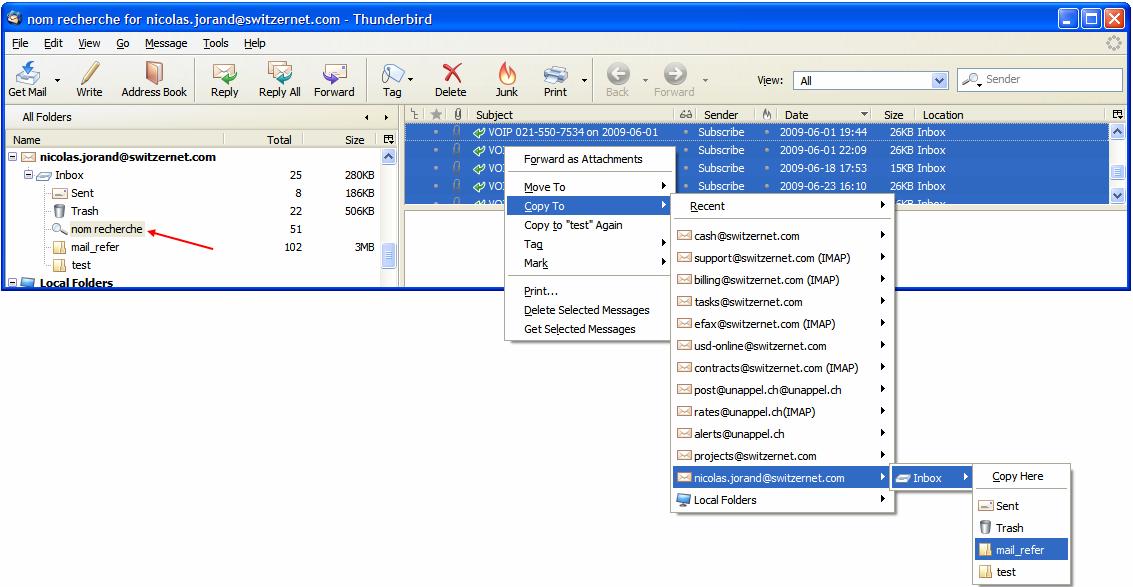
Maintenant que nous avons tous les e-mails qui doivent être traités, il nous faut récupérer les informations contenues dans leur header qui nous intéresse (l’e-mail du destinataire, le sujet et la date) et les mettre dans un tableau. Il y a deux possibilités qui s’offrent à nous, soit on passe par Outlook (voir Méthode via Outlook (plus simple)), soit on reste avec Thunderbird (voir Méthode via Mozilla Thunderbird (plus compliqué)).
[via_thunderbird] Méthode via Mozilla Thunderbird (plus compliquée)
La méthode qui suit est assez complexe, elle utilise une expression régulière et du script bash. En effet, Thunderbird n’offre pas la possibilité d’exporter le contenu d’un dossier comme le fait Outlook. Il faut donc aller le chercher sur le disque dur à l’endroit où il est sauvegardé et faire une expression régulière (regex) pour récupérer les champs qui nous intéresse. Et ensuite on peut ordonner ces informations triées à l’aide d’un script bash. Vous pouvez passer cette partie et aller directement à la Méthode via Outlook (plus simple)
1) Récupération des e-mails
Pour rappel le dossier qui contient les e-mails se trouve dans votre compte e-mail :
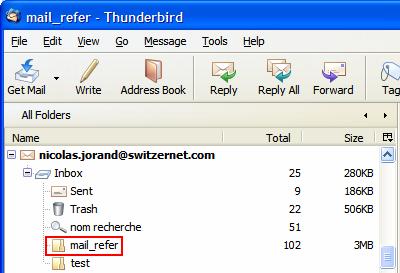
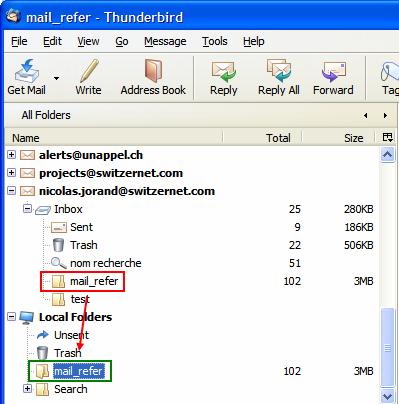
Pour que le contenu soit accessible "en clair" (c.à.d les e-mails sont lisibles), il faut le copier dans Local Folders. Il suffit de glisser (drag and drop) ce dossier dans Local Folders :
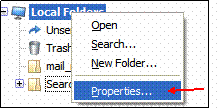
Il faut maintenant savoir où est stocké ce dossier (son adresse). Clique droit sur Local Folders->Properties :
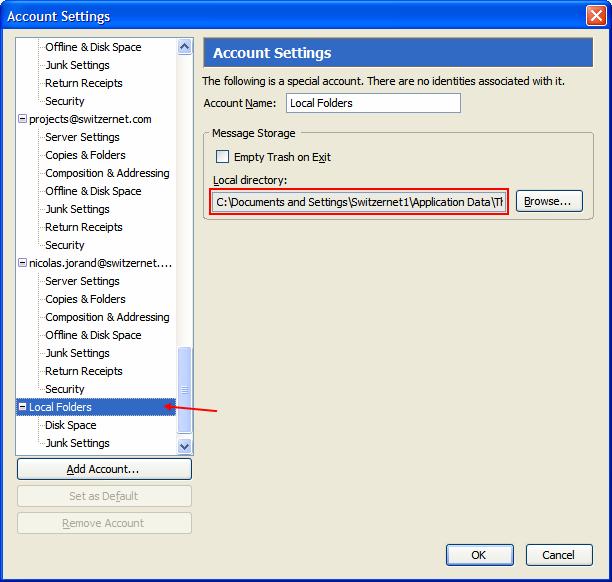
Nous pouvons voir l’adresse de stockage de Local Folders, copiez celle-ci (ctrl+c) :
Ouvrez n’importe quel dossier, par exemple My Documents puis entrez l’adresse que vous avez copié (ctrl+v) et enfin appuyez sur Enter :
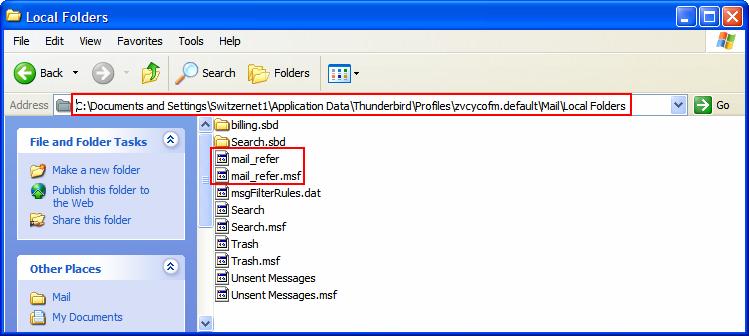
Vous pouvez voir votre dossier qui est stocké, une fois sans extension et une fois avec [msf]. Ce fichier avec l’extension msf s’occupe d’indexer les messages. C’est donc le fichier sans extension qui nous intéresse, car il comprend tous les e-mails avec leur contenu "en clair" comme nous pouvons le voir sur l’image suivante (l’entête de l’e-mail et le message) :
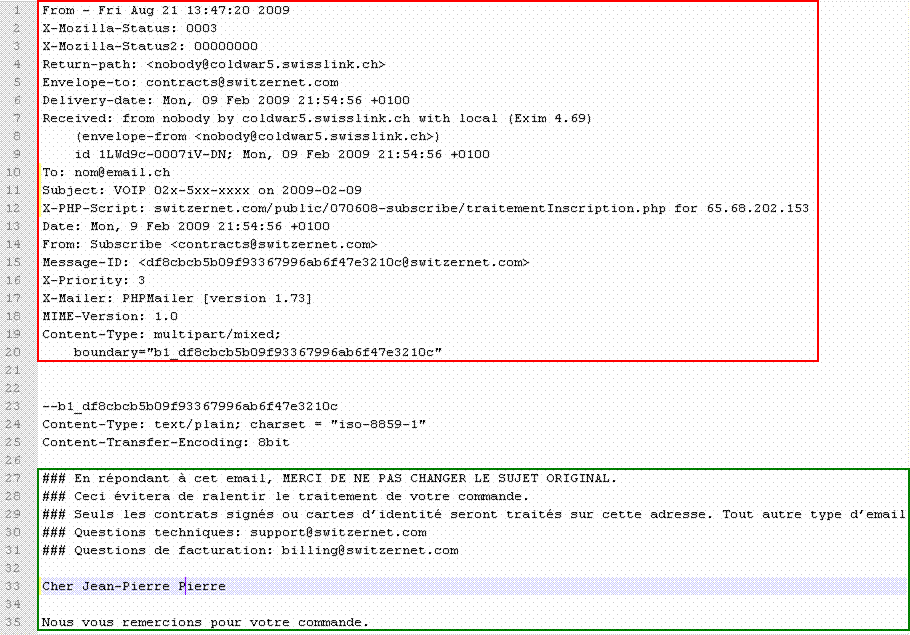
La première ligne de chaque message est identique : From – jour mois jj hh:mm:ss aaaa, c’est ce qui va nous permettre de repérer le début d’un nouveau e-mail.
Il ne faut pas
confondre le From
- qui signal le début d’un nouveau e-mail
avec From: qui nous dit qui est l’expéditeur
Mettez une copie de ce fichier (sans extension) dans un de vos dossiers, puis ajoutez lui l’extension .txt
2) Extraction des informations utiles
Il faut maintenant extraire de ce fichier les informations qui nous intéressent : la date (champ Date), le destinataire (champ To) et le sujet (champ Subject). Pour ceci nous devons utiliser une expression régulière (regex) pour récupérer les informations et un script bash pour organiser le tout dans un tableau. Voici au final ce que nous avons :
egrep "^(From |Date: |To: |Subject: )" mail_refer.txt | while read s; do if [ `echo $s | cut -d" " -f1` = "From" ]; then echo; fi ; echo -n "$s,"; done > data_refer.csv
Nous avons utilisé Cygwin pour exécuter cette commande.
Expression régulière
Celle-ci va nous permettre de filtrer les informations contenues dans le fichier en recherchant uniquement les lignes qui nous intéressent. Pour commencer voici quelques exemples, on a un fichier .txt avec les phrases suivantes :
Je joue au hockey
Tu joues à la petanque
Il joue aux cartes
On veut savoir si le mot hockey est dans le texte :
egrep "hockey" texte.txt
On commence avec egrep qui est le programme utilisé pour exécuter l’expression régulière. Ensuite, on met entre guillemets la regex (pour l’instant ce n’est qu’un mot, celui que l’on recherche). Et enfin le document dans lequel on effectue la recherche (texte.txt).
Voici ce que l’on obtient avec Cygwin, la phrase contenant le mot est affichée :
![]()
On voudrait maintenant savoir s’il y a les mots petanque et cartes :
egrep "petanque|cartes" texte.txt
Pour cela, on utilise la barre verticale : |. On peut la traduire par un OU, recherche de petanque OU cartes. Pour avoir ce caractère, il faut faire AltGr+7 !!!
![]()
Recherchons la ligne qui commence par Tu :
egrep "^Tu" texte.txt
Le chapeau : ^, indique que l’on recherche toutes les lignes qui commence par ce qui le suit (dans notre cas : Tu).
![]()
On peut combiner ces deux derniers (^ et |) pour rechercher les lignes qui commence par Je ou Il :
egrep "^(Je|Il)" texte.txt
![]()
Enfin, nous pouvons mettre le résultat dans un autre fichier :
egrep "^(Je|Il)" texte.txt > sortie.txt
C’est avec le signe > que nous pouvons le faire. Le fichier sortie.txt est créé, dans le même dossier que texte.txt, s’il n’existait pas. S’il existait déjà, l’ancien contenu est effacé et remplacé par le nouveau. Il est tout à fait possible d’indiquer un autre dossier pour enregistrer sortie.txt, il suffit d’indiquer le chemin pour y accéder :
egrep "^(Je|Il)" texte.txt > "votre_chemin/sortie.txt"
Et voici la regex que nous utilisons :
egrep "^(From |Date: |To: |Subject: )" mail_refer.txt > info_utile.txt
En s’aidant des exemples ci-dessus, on peut traduire cette regex par : « Toutes les lignes du fichier mail_refer.txt qui commence par From OU Date: OU To: OU Subject: sont mises dans le fichier sortie.txt ». La syntaxe du mot recherché est très importante (majuscule ou minuscule, espace, ponctuation, etc…). Comme on l’a constaté auparavant, il y a deux From : le premier est suivit d’un espace et nous signal le début d’un nouvel e-mail, le second est suivit de deux-points et indique qui est l’expéditeur. C’est bien le premier qui nous intéresse et qui nous aidera à trier les informations recueillies. Voici ce que nous avons dans info_utile.txt :
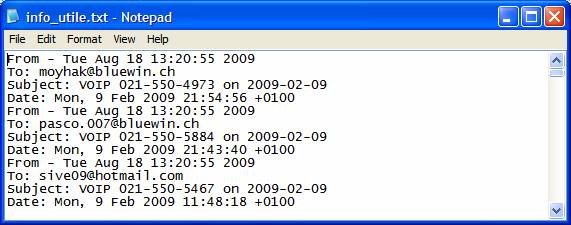
Remarque : pour en savoir un peu plus sur la syntaxe des expressions régulières, allez sur le site http://www.regular-expressions.info/reference.html
Script bash
Ce script va nous permettre d’ordonner les informations qui ont été récupérées par la regex. Pour l’instant chaque donnée recueillie est sur une ligne séparée, mêmes celles qui concernent le même e-mail (cf. image ci-dessus). On va donc mettre sur la même ligne les informations qui concernent le même e-mail et ceci à l’aide de ce script bash. La liste des commandes bash est disponible sur le site http://ss64.com/bash/. Tout d’abord voici quelques exemples :
While: c’est une boucle qui exécute du code tant que la condition qu’on a mise est vraie. On l’écrit comme suit :
while [ condition ]
do
command(s)...
done
Par exemple on veut afficher tous les chiffres (0-9) :
cnt=0; while [ $cnt –lt 10 ]; do echo $cnt; let cnt=cnt+1; done
On commence par déclarer une variable cnt à laquelle ont donne la valeur 0. Ensuite on a notre boucle, la condition est vraie si cnt est plus petit (-lt) que 10. Si la condition est vraie on fait ce qu’il y a entre do et done, c.à.d. on affiche la valeur de cnt (echo $cnt;) et on incrémente sa valeur de 1 (let cnt=cnt+1;).
Remarque : echo est la commande pour affiche quelque chose
let est la commande qui permet de faire des opérations arithmétiques
-lt est un opérateur arithmétique qui signifie plus petit que
Voilà ce que l’on obtient :
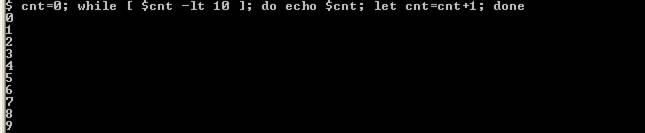
On peut afficher le résultat sur une seule ligne et en séparant chaque valeur par une virgule :
cnt=0; while [ $cnt –lt 10 ]; do echo –n "$cnt,"; let cnt=cnt+1; done
![]()
If : c’est un test qui exécute du code uniquement si la condition est vraie. On l’écrit comme suit :
if [ condition ]
then
command(s)...
fi
Reprenons l’exemple précédent et cette fois on veut afficher uniquement les chiffres qui sont plus petit que 5 :
cnt=0; while [ $cnt –lt 10 ]; do if [ $cnt -lt 5 ]; then echo –n "$cnt,"; fi; let cnt=cnt+1; done
On test donc si cnt est plus petit que (-lt) 5. Si c’est le cas, alors (then) on affiche cnt (echo –n "$cnt,";).
![]()
Cut : c’est une commande qui permet de couper une partie d’une chaîne de caractères ou d’un texte.
Prenons la chaîne de caractères je,tu,il,nous,vous,ils et coupons le nous :
chaine=je,tu,il,nous,vous,ils; echo $(echo $chaine | cut –d"," –f4);
On commence par déclarer la chaîne de caractères (chaine). Ensuite on a echo $( … ), ce qui va nous afficher le résultat obtenu avec ce qui se trouve à l’intérieur des parenthèses. Dans ces parenthèses on a un deuxième echo (echo $chaine) qui est suivit d’une barre verticale ( | ). Cette barre indique que le résultat de la commande précédent va être utilisé par une autre commande. Donc ici le résultat de echo $chaine ne sera pas affiché, mais utilisé par la commande cut.
Voici maintenant cette commande cut avec ses options. Le –d nous permet de couper la chaîne à chaque fois que le caractère entre guillemets apparaît (ici c’est la virgule). Une fois coupée, nous pouvons sélectionner une des parties avec le –f + l’index de cette partie (ici 4).
Voilà ce que nous avons :
![]()
On peut également appliquer ceci à une phrase en remplace la virgule par un espace. Dans la phrase Bonjour, aujourd’hui malheureusement il pleut. on peut couper le mot aujourd’hui avec la commande suivante :
Phrase=" Bonjour, aujourd’hui malheureusement il pleut."; echo $(echo $phrase | cut –d" " –f2);
![]()
Et voici le script que nous utilisons :
while read s; do if [ `echo $s | cut -d" " -f1` = "From" ]; then echo; fi; echo -n "$s,"; done
La structure est la suivante :
while [ condition ]
do
if [ condition ]
then
command ...
fi
command ...
done
Pour commencer, la condition du while est read s. La commande read permet de lire une ligne du fichier que nous avons obtenu avec la regex et de l’affecter à la variable s. Avec la boucle, on va lire le fichier tant qu’il y a une nouvelle ligne qui n’a pas encore été traitée. A l’intérieur de cette boucle, il y a un test (if) avec un cut dans la condition. Comme vu précédemment, la partie `echo $s | cut -d" " -f1` nous permet de récupérer le premier mot de la ligne. Ensuite, on regarde si ce mot est égal à From. Si c’est le cas, on faut un saut de ligne (echo sans rien après) et on ferme notre test avec fi. Enfin, on va afficher le contenu de la ligne et lui ajouter une virgule à la fin.
En fait, si la ligne ne commence pas par From, on l’affiche directement à la suite de la ligne qui précède (pas de saut de ligne à l’affichage).
Nous pourrions traduire ce script bash par : « Tant que toutes les lignes du fichier.txt n’ont pas été parcourues, on regarde si la ligne courante commence par le mot From. Si tel est le cas, on fait un saut de ligne et on affiche la ligne courante. Sinon, on affiche simplement la ligne courante sans saut de ligne. Chaque ligne du fichier.txt est séparée par une virgule à l’affichage. »
Combinaison regex et script bash
Maintenant mettons la regex avec le script bash :
egrep "^(From |Date: |To: |Subject: )" mail_refer.txt | while read s; do if [ `echo $s | cut -d" " -f1` = "From" ]; then echo; fi ; echo -n "$s,"; done > data_refer.csv
Pour les combiner, on ajoute une barre verticale ( | ) qui fait que le résultat de la regex va être traité par le script bash. Et une fois ce traitement effectué, on met le résultat final dans le fichier.csv. Voilà ce que ça donne :
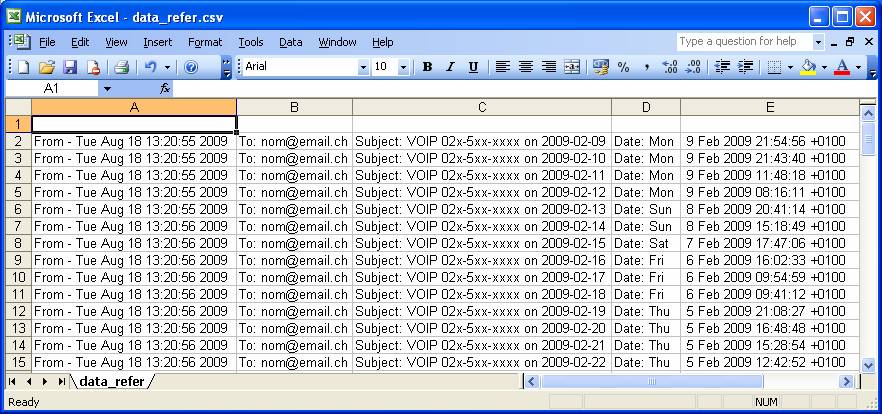
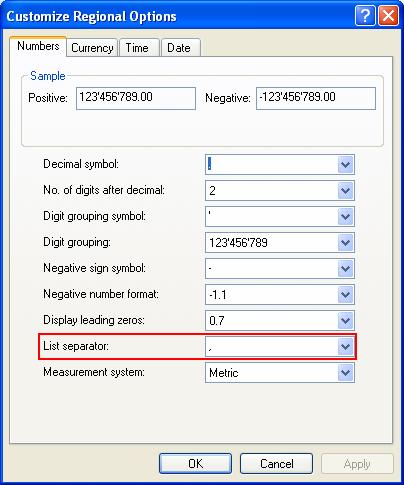
Dans le cas où les différentes informations ne sont pas dans des colonnes séparées, il faut modifier un paramètre du PC. Pour ceci, allez dans Start->Control Panel->Regional and Language Options->Customize et dans le champs List separator mettez une virgule. Ensuite faites deux fois Apply et Ok pour valider la modification :

Exécution de la commande
La commande a été exécutée avec Cygwin. Démarrez Cygwin et tapez cd :
Ensuite allez dans le répertoire où se trouve votre copie du fichier contenant les e-mails (ici c’est mail_refer.txt) et glissez-le dans Cygwin (Drag and Drop) :

Effacez le \nom_du_fichier.txt et appuyez sur Enter :

Vous vous trouvez maintenant dans le bon répertoire. Il ne vous reste plus qu’à copier la commande et appuyer sur Enter :
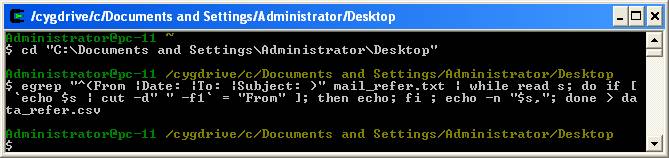
Et voilà, votre fichier.csv est créé.
[via_outlook] Méthode via Outlook (plus simple)
Outlook offre la possibilité d’export le contenu d’un dossier dans un fichier. Allez dans l’Inbox de votre compte e-mail (ici aussi utilisez le compte IMAP). Vous verrez le dossier que vous avez créé qui contient les e-mails à traiter :
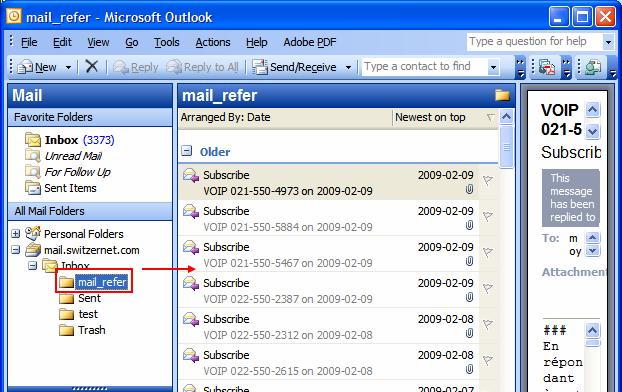
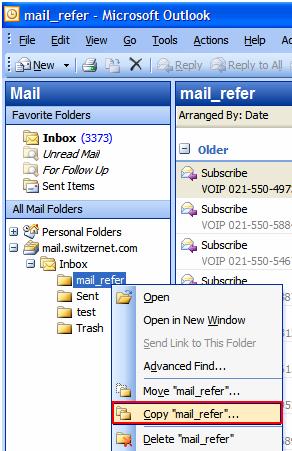
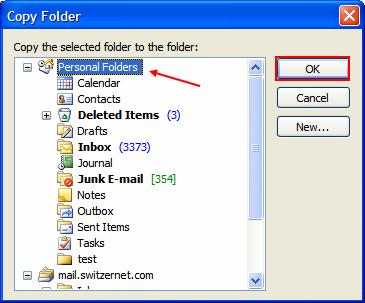
Ce dossier doit ce trouver dans Personal Folders, il faut donc copiez notre dossier dans Personal Folders. Clique droit sur le dossier->Copy "nom_dossier" puis sélectionnez Personal Folders et enfin Ok :
Maintenant nous pouvons exporter le contenu du dossier (donc les e-mails). Allez dans File->Import and Export :

Sélectionnez Export to a file puis Next, choisissez Microsoft Excel puis Next :
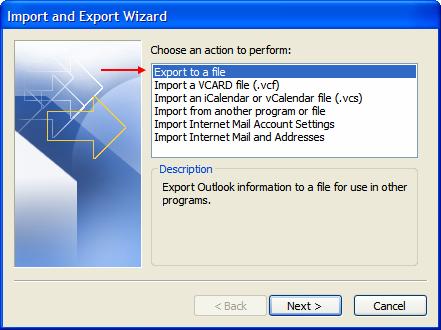
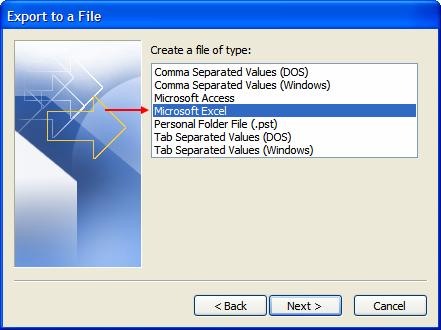
Sélectionnez le dossier que vous voulez exporter puis Next, choisissez le dossier dans lequel vous voulez enregistrer le fichier d’exportation et son nom puis Next :
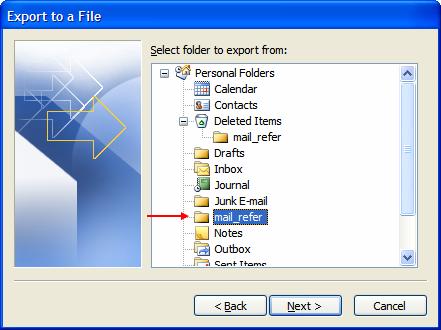
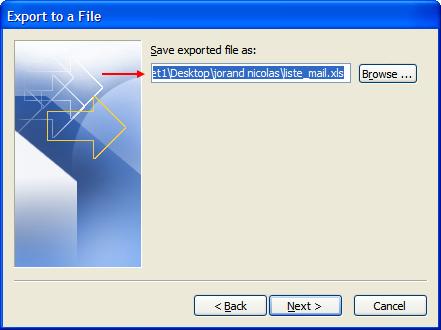
Vérifiez que le mappage soit correct, pour ceci appuyez sur Map Custom Fields et faites un Clear map et glissez (drag and drop) les champs qui nous intéressent (Subject et To:(Address)) puis Ok et Finish :
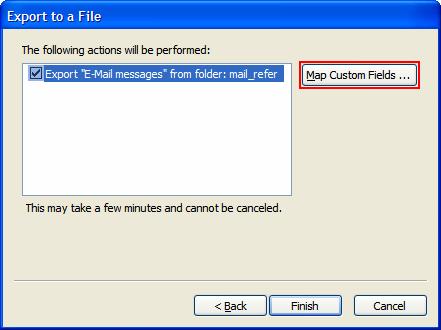
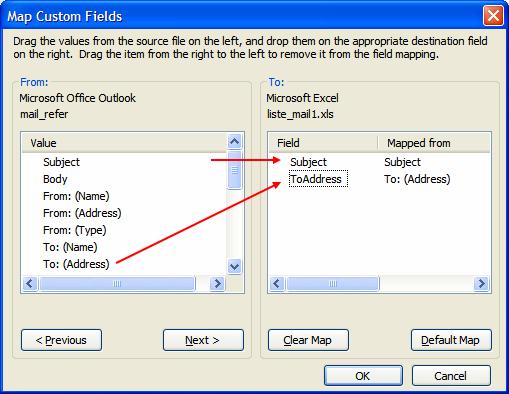
Le fichier Excel créé a deux colonnes, une avec le Subject et l’autre avec To:(Address) comme dans l’exemple suivant :
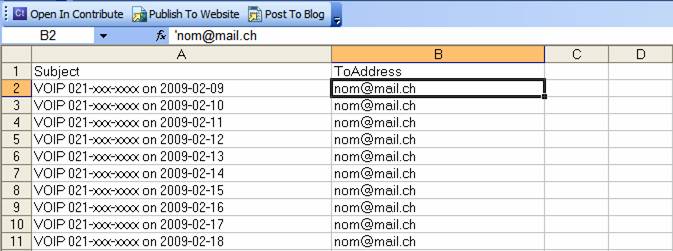
Nous avons également besoin de la date, mais malheureusement nous ne pouvons pas la récupérer avec l’export. Pour l’avoir dans notre fichier Excel, allez dans Outlook et dans le dossier contenant les e-mails. Cliquez sur un des e-mails puis faites ctrl+a et ctrl+c (pour les copier) :
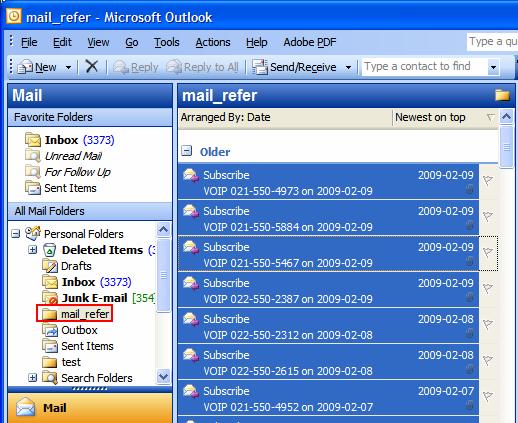
Dans Excel, sélectionnez la case C1 et faites ctrl+v. Vous vous trouverez avec ceci (vérifiez que les sujets correspondent, colonne A égale colonne D) :
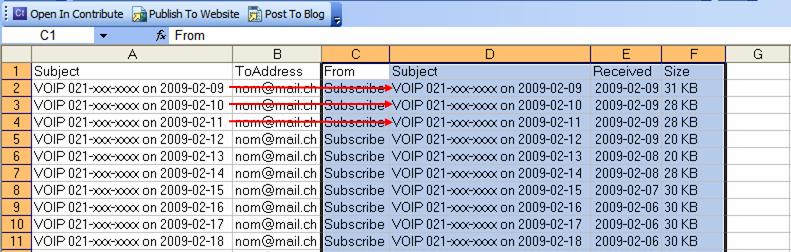
Si tout est bon, supprimez From (colonne C), Subject (colonne D uniquement) et Size (colonne F) pour vous retrouver avec ce qui suit :
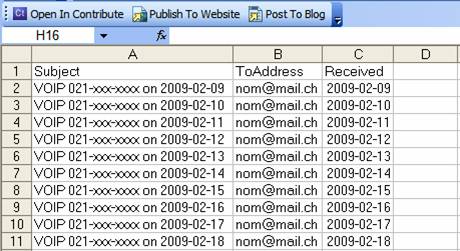
Et voilà, c’est terminé. Vous pouvez sauvegarder le fichier et le fermer.
* * *